Aggregate scores¶
Aggregated scoring function is an automatic scoring system. It generates the overall proficiency, dominance, and immersion levels for each language the participant has learned and their multilingual language diversity score. These aggregated scores of each participant will help the researcher to arrive promptly at a useful estimation/classification of different types of multilingual speakers.
Aggregate scores calculation¶
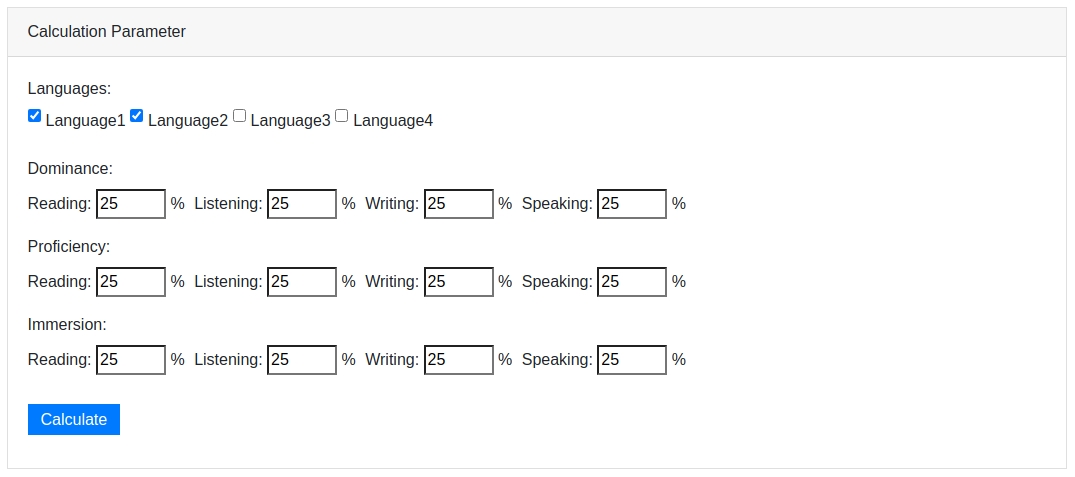
First, you will need to set the weight of the four linguistic components, Reading, Writing, Listening and
Speaking on the Calculation Parameters panel. The rationale is that researchers may have different emphases on
various linguistic components in their studies. Therefore, a weighted aggregated score allows higher flexibility in
given instances: for example, a study focusing on illiterate bilinguals may only consider speaking and listening,
with 50% weighting to each of them but 0% for reading and writing.
Language proficiency¶
The aggregated score of language proficiency is based on the weighted sum of the participant’s self-rating of his/her proficiency levels on different linguistic components of a language (Question 15: Rate your current ability in terms of listening, speaking, reading, and writing in each of the languages you have studied or learned).
A participant’s overall proficiency score of the ith language can be written as:
\[Proficiency_{i} = \frac{1}{7}\sum_{j=\{R,L,W,S\}}ω_{j}P_{i,j}\]
Here, {R,L,W,S} stands for Reading, Listening, Writing and Speaking components of a language.
Pi,j stands for a participant’self-rated proficiency level to the jth component of his/her ith language.
Since it is rated on a 7-point Likert scale, we use a scaling factor of 1/7 to normalize it into a range between zero and one (with 1 indicating native-like language proficiency level).
ωj represents a weight assigned to the jth linguistic component.
Language immersion¶
The aggregated score of immersion for each language that the participant knows, is based on their Age, Age of Acquisition (AoA), and Years of Use of the language (Question 7 of LHQ3: Indicate your native language(s) and any other languages you have studied or learned, the age at which you started using each language in terms of listening, speaking, reading, and writing, and the total number of years you have spent using each language).
A participant’s overall immersion score of his/her ith language can be written as:
\[Immersion_{i} = \frac{1}{2}[\sum_{j=\{R,L,W,S\}}ω_{j}(\frac{Age-AOA_{ij}}{Age})+(\frac{YoU_{i}}{Age})]\]
Here, Age is the participant’s current age in years.
AOAi,j stands for the participant’s age of starting using her ith language in terms of the jth component (e.g., reading).
YoUi stands for her total number of years using the ith language.
{R,L,W,S} stands for Reading, Listening, Writing and Speaking components of a language.
ωj represents a weight assigned to the jth linguistic component.
In addition, we apply a scaling factor (1/2) to the function to ensure AoA and YoU have equal weight on calculating the overall immersion score, and to normalize the score to a range between 0 and 1 (with 1 indicating the most native-like immersion level for a language).
Language dominance¶
The aggregated score of dominance is based on both the participant’s self-reported proficiency (Question 15, see above) and the time (hours per day) spent on different linguistic components of each language (Questions 18, Estimate how many hours per day you spend engaged in the following activities in each of the languages you have studied or learned; Question 19. Estimate how many hours per day you spend speaking with the following groups of people in each of the languages you have studied or learned).
A participant’s overall dominance score of his/her ith language can be written as:
\[Dominance_{i} = \sum_{j=\{R,L,W,S\}}ω_{j}[\frac{1}{2}(\frac{P_{ij}}{7})+\frac{1}{2}(\frac{H_{ij}}{K})]\]
Here, Pi,j stands for a participant’self-rated proficiency level to the jth component of his/her ith language.
Hi,j stands for the total estimated hours per day a participant spent on the jth linguistic aspect (e.g., speaking) of his/her ith language.
K is a constant serving as a scaling factor, currently set to be 16.
Another scaling factor 1/2 is applied to the function to ensure the proficiency and the daily usages of a language to have equal weight on calculating its dominance score.
{R,L,W,S} stands for Reading, Listening, Writing and Speaking components of a language.
ωj represents the weight assigned to the jth linguistic component.
Ratio of dominance¶
A word of caution regarding the aggregated dominance scores: although useful for within-subject comparison of language dominance, one should be careful about using these scores for the comparison across participants. The main reason is that considerable individual differences on participants’ self-estimation of their daily usage of one or more languages might exist. Some participants may be more liberal when estimating their time on language activities, thus giving overall higher dominance scores; whereas others are more conservative when estimating.
To address this potential pitfall, we introduce another new measurement of language dominance, expressed as the ratio between the two dominance scores, as
\[Ratio_{Dominance} = \frac{Dominance_{i}}{Dominance_{1}}\]
This measurement provides the relative ratio of the dominance score of each language (Dominancei) against that of the first (typically native, Dominance1) language of the participant. It can give researchers a standardized/normalized estimate of language dominance that is more comparable across participants (akin to Z scores). Using the ratio, the researchers can easily determine if a participant is a balanced multilingual, or having one language dominant over another language.
MLD score¶
The Multilingual Language Diversity (MLD) score allows researchers to better describe the participant’s bilingualism level through their language usage in terms of context and diversity.
The MLD score is calculated as follows:
For the ith language reported by a participant, LHQ3 calculates an aggregated dominance score (Dominancei) based on both the participant’s self-reported proficiency and frequency of usage time (hours per day) on different components of the language. A temporary variable for the ith language that we term as Proportion of Dominance (PD i):
\[PD_{i} = \frac{Dominance_{i}}{\sum_{i=1}^{n}Dominance_{i}}\]
where n represents the total possible languages a participant has learned. PDi represents the proportion of a languagei (ith language) that is dominant in a participant’s language environment/usage.
The participant’s overall MLD score is then calculated in a form of Shannon Entropy.
\[MLD = -\sum_{i=1}^{n}PD_{i}\log_2(PD_{i})\]
MLD will be in a range between 0 and 2.
More information¶
Need more information? See Aggregate scores and MLD scores.